关于DAX计算,会表现为你在编写 计算列 或 度量值 时直接应用,也是建立对CALCULATE正确思维模式的基础。
关于上下文(context),其含义为:周围环境。也就是说,要确定某种含义,必须考虑到它所处于的环境中,上下文正是这种周围环境。
DAX的计算也一定在某种环境中,那就是计算所处的计算上下文(Evaluation Context),具体而言分为:行上下文(Row Context)和筛选上下文(Filter Context)。
理解DAX的计算原理
DAX计算就其本质,可以理解为在建立了关系的多个表构成的数据模型上,DAX通过筛选,找到需要进行计算的一个数据模型的子集,然后完成聚合型计算。下面详细解释。
如果你刚从Excel过来,那必须要了解:DAX包含了一些和Excel函数类似的函数及用法,但DAX更多地提供了专有的函数和用法。
最重要的是DAX在计算上的原理和Excel是完全不同的,这也是Excel用户刚刚接触DAX后最大的问题所在,那就是带着Excel函数的思维模式来套DAX。
需要强调的是:如果说Excel函数的计算是基于单元格的,那么DAX的计算是基于 列 进行的。
DAX基于列运算,也就保证其能大规模地处理数据。想象一下,一个日期列有一万个日期,如果是基于单元格计算,那要计算一万次,而基于列计算,也许只要1次。DAX强大的根本也正在于此。
那么问题来了:DAX如何完成对特定行单元格的计算,或者说DAX如何在特定的行进行计算。
也就是说:
DAX 具备粗犷式地按列运算,这必须做到,确保DAX可以完成大规模计算。
DAX 具备细腻式地按行运算,也必须做到,确保DAX可以完成精确地计算。
DAX在设计上,必须兼顾这两种目标。DAX提供了两种关键特性:一种是筛选,一种是迭代。
DAX筛选,就是按照一定规则(筛选规则,如切片器,Filter等)选择出模型的一个子集。
DAX迭代,就是进一步针对这个子集的每一行进行轮询处理(如:2017年的订单表每行的单价乘以数量便得到销售额)。
DAX计算,则直接完成某种聚合运算(如:SUM刚刚的每一行得到总销售额)。
重要的事情值得再次强调:
DAX计算(往往就是CALCULATE),在本质上就是筛选出数据模型的子集,然后对行进行迭代处理后进行聚合运算。(其中的各个步骤可能省略或跳过)
注意:如果被筛选得只有一行一列,也就是出现行列交叉处,即单元格。也就完成了对单元格的处理。
筛选上下文,正是完成筛选的关键机制,而行上下文,正是完成迭代中行中计算的关键机制。
理解行上下文
【第一种情况】DAX表达式对列进行操作,通常会写下如下的表达式:
Gross Profit := SUMX ( Sales, Sales[Amount] – Sales[TotalCost] )
在上述表达式中,Sales [Amount]和Sales [TotalCost]是列引用。即:用列的名称表示列值,在示例中,可以获取SUMX当前迭代行的Sales [Amount]值。
可以理解为,SUMX 首先对每一行逐条计算。计算结果会放在一个虚拟列中。 SUMX 的迭代:就是 SUMX 在对虚拟列中的结果一个一个的进行加和。 而当前迭代行,就是 SUMX 现在加到哪一行,这一行就是当前迭代行。
【第二种情况】DAX使用列引用来制定某些功能对列执行操作,如以下计算产品名称数量的度量:
NumOfAllProducts := COUNTROWS ( VALUES ( Product[ProductName] ) )
`VALUES(<TableNameOrColumnName>)` 返回一列表或包含列中不同(唯一)值的表。 (我的理解是,VALUES 返回一列,而这一列进行了去重。 如果返回一个表,则返回完整表,不会去重。) TableNameOrColumnName :要从中返回唯一值的列或表。 返回值 整个表或包含一列或多列的表。 如果参数是单列,则为一列唯一值。 如果参数是表表达式,则结果具有相同的列,并且不会删除重复的行。 备注: VALUES类似于DISTINCT,但它可以有一个额外的空行,以防表与其他表存在至少一个一对多的关系,其中存在违反参照完整性的情况。
在这种情况下,Product [ProductName]不检索特定行的ProductName值。相反,使用列引用来告诉VALUES要使用的列本身
换句话说,你引用列,而不是它的每个行值。
(我的理解是:(引用列值)就是表达式中,需要知道列中每个值是什么,是“100”还是“1000”,关心的是这个值是多少,因为要对这些值进行计算。
(引用列本身)就是表达式中,不关心列中的值是什么,例如要进行 Count 计数,只关心值是不是相同,不关心值本身是多少。)
综合上述两种情况,可以发现 列引用 是一个有点模糊的定义,因为不管是引用了特定行中的列值,还是引用了完整的列本身,都在用相同的语法,这就很难从意思上区分开到底是在用哪一种。然而也正是这种模糊为DAX表达式带来好处,就是易于阅读(流畅地阅读);但我们必须时刻清楚:现在使用的是列值还是列本身(列引用)。
因此,作为DAX编写者,你必须一边编写DAX,一边同时思考,当前正在使用DAX列引用,还是列引用下的每个值。如果将这种思维变成了自然的感觉也就进入了DAX新的阶段。
这个区分就在于:DAX计算使用的列引用是不是位于一个行上下文中。
当您使用列引用来检索给定行中的列的值时,需要一种方法来告诉DAX要使用的行,用于计算该值。换句话说,您需要一种方法来定义表的当前行。这个概念就是“当前行”的行上下文。
无论是显式地(使用迭代器)还是隐式地(在计算的列中)遍历表,都是在使用行上下文:
- 在计算列中编写表达式时,将为每一行计算表达式,为每行创建行上下文。
- 当使用像FILTER,SUMX,AVERAGEX,ADDCOLUMNS等属于迭代器函数的任何一个DAX函数。
如果行上下文不可用,试图直接对列引用进行计算就会产生错误。例如:在DAX度量值中仅写入列引用,就会导致这种错误,因为行上下文不存在。如下所示的方法无效:
SalesAmount := Sales[Amount]
为了使其工作,您可以对该列进行聚合运算。事实上,SalesAmount的正确定义也应该是:
SalesAmount := SUM ( Sales[Amount] )
SUM的本质是SUMX的变体写法,SUMX就属于迭代器函数,将遍历Sales[Amount] 列的每行,并通过行上下文,提出当前的行值(由于位于行列交叉,也就是单元格值),然后进行聚合累加运算而得到最后结果。
迭代器函数可以完成更复杂的计算,就是嵌套起来使用。例如,可以写:
AverageDiscountedSalesPerCustomer :=
AVERAGEX (
Customer,
SUMX (
RELATEDTABLE ( Sales ),
Sales[SalesAmount] * Customer[DiscountPct]
)
)
在最内层的表达式中,引用Sales [SalesAmount]和Customer [DiscountPct],即来自不同表的两列。可以顺利正确地执行操作。这里有两个迭代器,分别产生行上下文:AVERAGEX在Customer表进行迭代并引入第一套上下文,SUMX在Sales表上进行迭代并引入另一套行上下文。此外,值得注意的是,RELATEDTABLE相关行还使用行上下文来确定要返回的相关行集合。事实上,RELATEDTABLE(Sales)返回当前客户的销售记录,其中“当前”是指AVERAGEX当前迭代的客户。
筛选上下文
筛选上下文是在DAX表达式在计算开始之前就应用于数据模型的一组筛选器。例如,在数据透视表中使用度量值时,它会为每个单元格产生不同的结果,这是因为相同的表达式在将基于数据模型的不同子集进行计算。微软将数据透视表的用户界面应用的筛选器以及可以在度量值中写入的DAX表达式应用的其他筛选器统称为查询上下文。实际上,这些筛选器的效果几乎是相同的(实际差异对于这里来说并不重要),因此我们简单地将筛选上下文定义为限制DAX表达式计算(通常是度量值)的一组筛选器,不管它们是如何生成的。
例如,下图中突出显示的单元格具有2007年的筛选器上下文,颜色等于Black,产品品牌等于Contoso。这就是为什么它的度量值不同的原因。
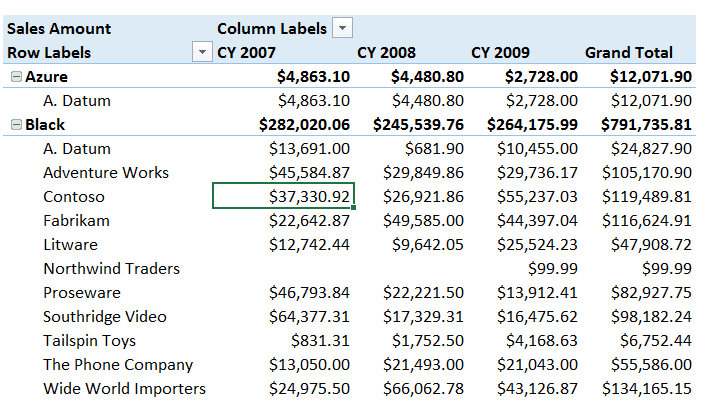
可以通过使用CALCULATE得到相同的计算效果。例如,以下DAX查询中进行的DAX计算正返回上一图片中突出显示的单元格的相同值。
DAX查询不是本文的主题,可以暂时忽略对它的理解。这里为了揭示透视表的界面操作和DAX计算时设置筛选器可以达到相同的效果,是等价的。
EVALUATE ROW ( "Sales Amount", CALCULATE ( [Sales Amount], 'Date'[Calendar Year] = "CY 2007", Product[Color] = "Black", Product[Brand] = "Contoso" ) )
通常,在透视表的每个单元格都有不同的筛选上下文,这是由用户界面(如Excel中的数据透视表)隐式定义的,也可以使用CALCULATE显式地通过某些DAX表达式进行定义。
应用于Excel中的数据透视表或Power BI Desktop或Power View的任何用户界面元素都会作为筛选器影响筛选上下文,但这并不直接影响行上下文。
筛选上下文实际是数据模型上的一组筛选器。任何DAX表达式始终都在筛选上下文中执行。如果筛选上下文为空,DAX表达式在整个数据模型中运行。当筛选上下文不为空时,它限制DAX表达式在被筛选后的数据模型中运行。
最后,值得注意的是可以把筛选上下文理解为一组等效的筛选器(事实也正是如此)。所在,在提到筛选上下文的时候,其实是一组筛选器。
理解筛选的传播
行上下文不会通过关系传播。如果表中有行上下文,则可以使用RELATEDTABLE在关系的多方迭代表的行,也可以使用RELATED访问父表(关系一方)的行。
应用于表列的筛选器会影响该表的所有行,以过滤满足该筛选器的行。如果将两个或多个筛选器应用于同一个表列,则将它们视为逻辑与条件,只有满足所有筛选器的行才能保留在该筛选上下文中继续由DAX表达式计算。
根据关系的方向,筛选上下文会通过关系从关系一方自动传递到关系多方。
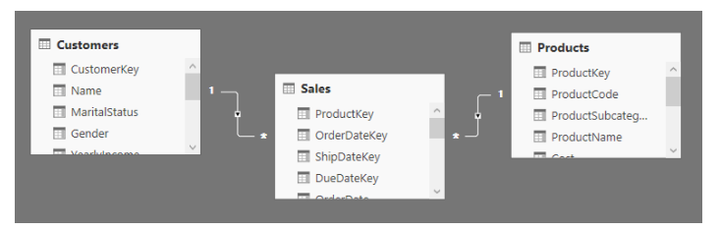
在Excel的Power Pivot中,这样一个方向只有一对多,所以在一个关系的一边应用的筛选器会影响关系多方的表行,但是筛选器不会按相反的方向传递。例如,考虑一个模型,其中有两个表,Product和Customer,每个表与Sales表具有一对多关系。通过筛选器过滤产品也就相当于过滤了(筛选的传递)产品的销售,但不能过滤(筛选不会继续传递)购买这些产品的客户。
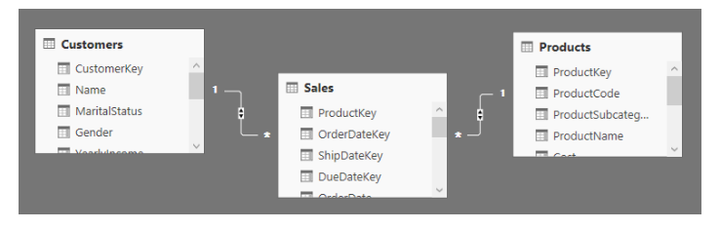
在Power BI Desktop中,可以启用双向交叉筛选。通过启用双向交叉筛选器,一旦过滤了一个表,也就自动过滤了关系链上的所有表。例如,当过滤产品上的行时,会隐式地过滤Sales和Customer,以这种方式过滤出产品相关联的客户。
总结
- DAX计算的本质是基于筛选出数据模型的一个子集进行迭代后进行聚合型计算(可以忽略或跳过其中环节)。
- DAX计算的完成有赖于筛选上下文和行上下文,它们统称为计算上下文。
- 编写DAX表达式时,通过控制行上下文和筛选上下文已达到预期的运算。
- 行上下文不会通过关系自动传递,而筛选上下文将独立于DAX代码遍历关系并产生筛选传递的效果。
- 可以使用DAX函数(如CALCULATE,CALCULATETABLE,ALL,VALUES,FILTER,USERELATIONSHIP和CROSSFILTER)来控制筛选上下文及其传递,这些在后续的篇章中继续说明。